.png)
.png)
This technical writeup provides details on how we improved the Halo2-ICICLE integration, resulting in an almost-native GPU implementation and record breaking performance numbers. As usual, the ICICLE-Halo2 code can be found on our GitHub.
Intro
The Halo2 proving system was created by the ZCash team and it’s one of the most popular zk-SNARKs. After that, different versions and forks of Halo2s emerged by different teams. Notable versions are zcash-halo2, pse-halo2, ezkl-halo2 and axiom-halo2. Today we are releasing our own fork of ezkl-halo2 with up to 25x performance boost. While we built on top of ezkl-halo2, our changes are still applicable to other versions.
Background: Halo2 Overview
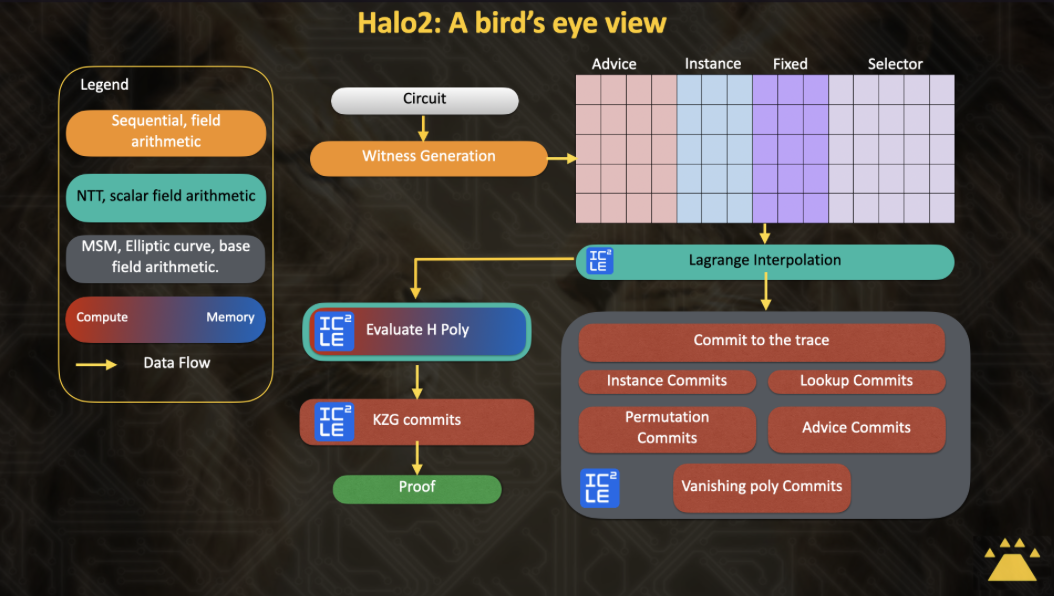
We start by breaking down the Halo2 Prover into several major phases:
- Circuit Definition and Setup: The circuit is defined using custom gates, lookups and permutation constraints. Then a Proving Key will be generated for the circuit.
- Witness Generation: Halo2 uses the plonkish arithmetization, which allows expression of various custom gate constraints, lookup constraints and the permutation constraints. Note that the arithmetization or the process of breaking down a complex program into a bunch of connected satisfiable algebraic constraints is a highly sequential process. Hence the intermediate values that are produced in this stage that act as “witness’' for the computation are generated serially, and such computations are harder to accelerate using parallel programming on a GPU. In this work we didn’t focus on optimizing the witness generation.
- Polynomial Evaluations: Once the advice columns are filled in the witness generation phase, a polynomial representation of the columns is constructed using Lagrange interpolation or Number Theoretic Transforms (NTT)
- Commit to trace: Following the interpolations, the trace values are committed using MSM (Multi Scalar Multiplication). It is by now well known that MSM is highly parallelizable and moreover we can use batching methods to perform all of these commitments together.
- Custom Gates, Permutation and Lookups Evaluations: roughly speaking these can be described as follows:
- Gate constraints: These are constraints over the advice and fixed columns which are enabled/disabled by a boolean value in the selector columns. In general the constraints can apply simultaneously to groups of contiguous rows in the matrix.
- Permutation constraints: This enforces that specific groups of cells that are connected by wires have the same value.
- Lookup constraints: If a lookup table is used in the verification of a constraint, the corresponding cell values in the advice columns are constrained to be in a set membership
- Commitments and Proof Generation: After constructing and satisfying the constraint system with witness values, Halo2 moves to the commitment phase. It uses polynomial commitments (KZG or IPA) to construct the final proof.
By default you can easily accelerate commitments, lagrange interpolations and vector operations using ICICLE API. EZKL's main branch already has ICICLE integration with MSM and NTT accelerations. However gate, permutation and lookup constraints are still a big bottleneck and it’s not straightforward to move them to GPU because of the complicated structure of the constraint evaluations.
Breaking the Speed Barrier with ICICLE
ICICLE is a cutting-edge cryptography library engineered to accelerate advanced algorithms and protocols — starting with ZKPs — across diverse compute backends, including GPUs, CPUs, Metal, and more. It supports multiple frontends in C++, Rust, and Go, enabling seamless integration with various development environments, so one can choose between 3 popular languages and utilize multiple hardware by only writing one code.
Accelerating Halo2
With the latest ICICLE integration in the EZKL-halo2 main branch, we’ve already accelerated MSM and NTT operations on the GPU. Now, by offloading gate, permutation, and lookup constraint evaluations to the device as well, we've eliminated one of the major remaining bottlenecks. Right now most of the prover has become GPU-native, unlocking substantial performance gains overall.
Gate and Lookup Constraints
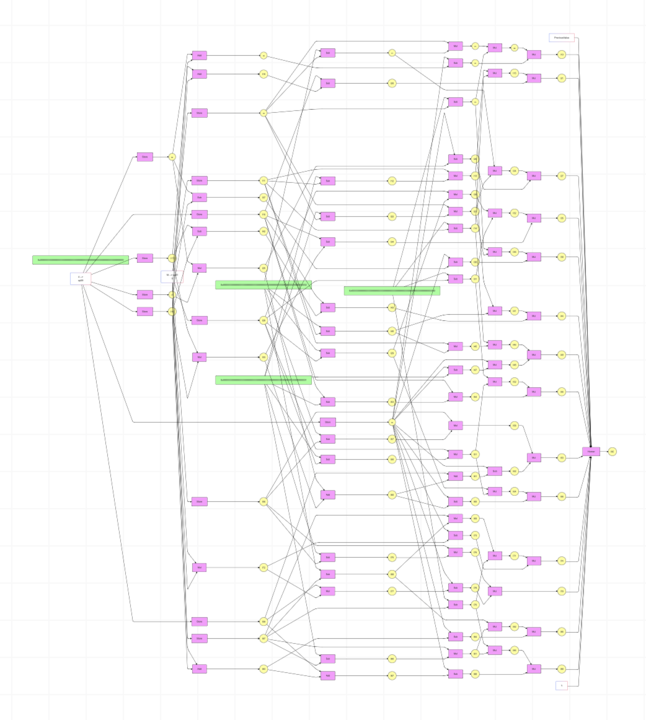
In Halo2, circuits can include lookups and custom gates. These components often become the main bottleneck during proving, especially as the number of lookups increase. 2^k calculations must be evaluated for each lookup and custom gates. When dealing with large circuits, this evaluation process becomes extremely computation and memory intensive. To address this, we developed a new custom CUDA kernel designed specifically for evaluating values at given indices. However, with naive implementation, we encountered a significant memory issue. Even with relatively simple custom gates, the memory required for intermediate values grew dramatically, quickly becoming unsustainable.
For example, consider the custom gate on the left. It requires allocating memory for 2^k × 100 intermediates, each 64 bytes in size. When k is 22 as an example, this results in approximately 26 GB of GPU memory usage. Even high-end GPUs like the 4090 cannot accommodate this. We solved this issue by processing the data in batches. Since these batches execute very quickly on the GPU, we were able to eliminate the memory bottleneck with a negligible trade-off in execution time.
Data Conversion and Data Transfer
One of the biggest problems with moving any code to the GPU is data transfer and conversion. To be able to use ICICLE and utilize CUDA you need to convert your data to ICICLE type and move it to the device. In most cases preparing data for the CUDA kernel will take a lot more time than executing the kernel itself.
Data conversion can take too much time due to calling a from function 2^n times. In most cases it’s possible and better to alter the memory directly with transmute calls in Rust. This allows the developer to change the type of the existing memory if the developer can guarantee it’s okay to use. It’s practically 100% speedup because transmute calls take only 20–30 ns while the same conversion takes 100ms when done in a naive way.
Data transfer speed is limited by hardware. Therefore it’s crucial to avoid data transfer whenever possible. This was the initial motivation for us to build Groth16 from scratch instead of simply replacing MSM and NTT calls in existing implementations.
MSM and NTT
MSM and NTT are being used in many proving systems. In Halo2, MSM is being used for commitments and NTT is being used for Lagrange Interpolation. You can already use ICICLE API in EZKL by setting the icicle feature and flag.
VecOps
There are many places we need to add, multiply and subtract two vectors element-wise or inverse a vector. These tasks are highly parallelizable on GPU. Calling VecOps API in ICICLE instead of using CPU to processes long arrays gave 200x boost on average (size 2^22)
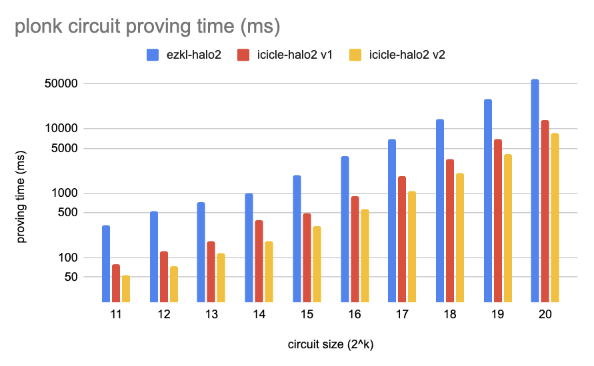
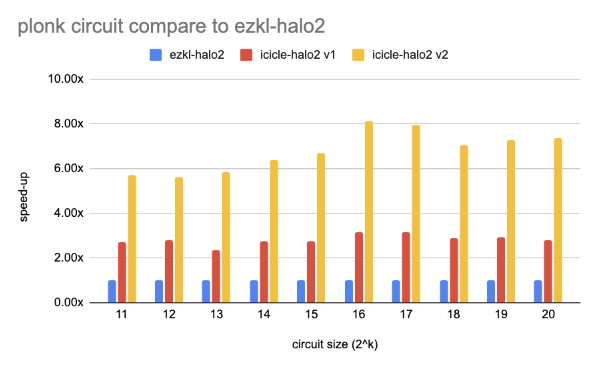
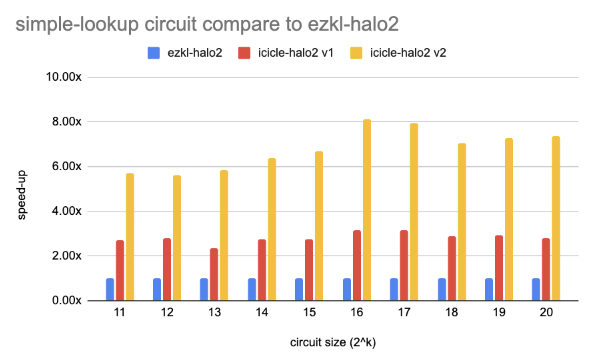
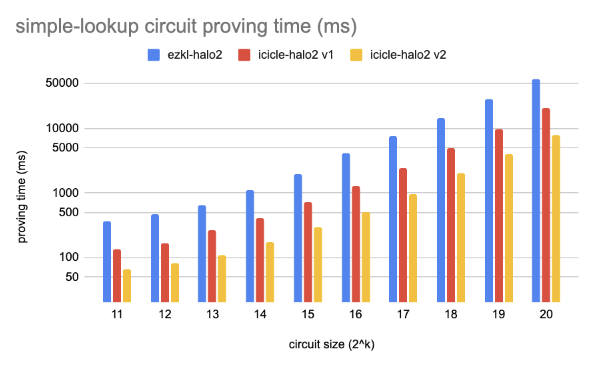
Performance Benchmarks & Results
We used the example and benchmark circuits in the Halo2 to compare the performance in different types of circuits on NVIDIA RTX 4080.
- Simple Lookup: Defines a lookup table that doubles input values and verifies this relation using both a lookup constraint and a simple identity gate.
- Plonk: Implements a gate that supports both multiplication and addition. It repeatedly computes a^2 + a, verifies correctness using gate constraints.
- Lookups: Defines a lookup-heavy computation using a simple 8-bit lookup table and multiple redundant lookup constraints to inflate the degree of the constraint system.
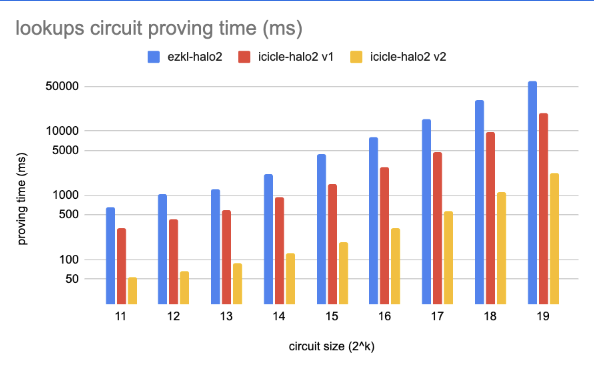
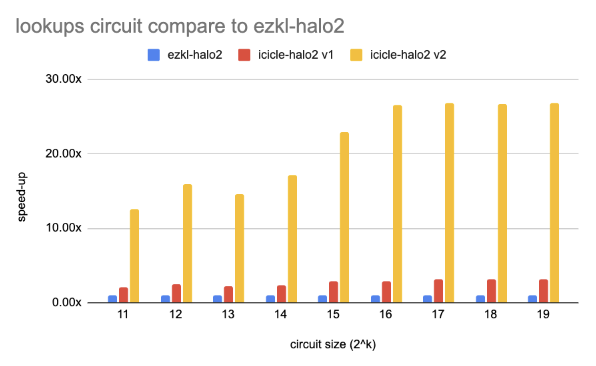
How to use icicle-halo2
If you are already using EZKL or ezkl-halo2 the only thing you need to do is change dependency in Cargo.toml. Icicle-halo2 is a fork of ezkl-halo2 and right now there is no conflict with main branch.







