.png)

TL;DR: All our benchmarking data is, from now on, publicly available. In this blogpost we use a new open source FPGA accelerator for Grøstl hash to demonstrate how to work with our database. This is a follow up work to our ZK-Score proposal.
Benchmarking
Benchmarking is a critical piece of information for any ZK practitioner. Transparent and extensive benchmarking enables developers and researchers to select and use the most efficient hardware implementations for their use cases, and to validate and compare implementation results. In continuation with ZK-Score, and leveraging our unique position in the space, we focus on hardware benchmarking of important primitives: NTT, MSM, and Hash functions.

The Benchmarking Toolkit
At its core, the benchmarking toolkit is an SQL database which stores benchmarking data for different ZK primitives. The SQL tables record data regarding the hardware platform, finite field information, and benchmark data relevant to the specific primitive.
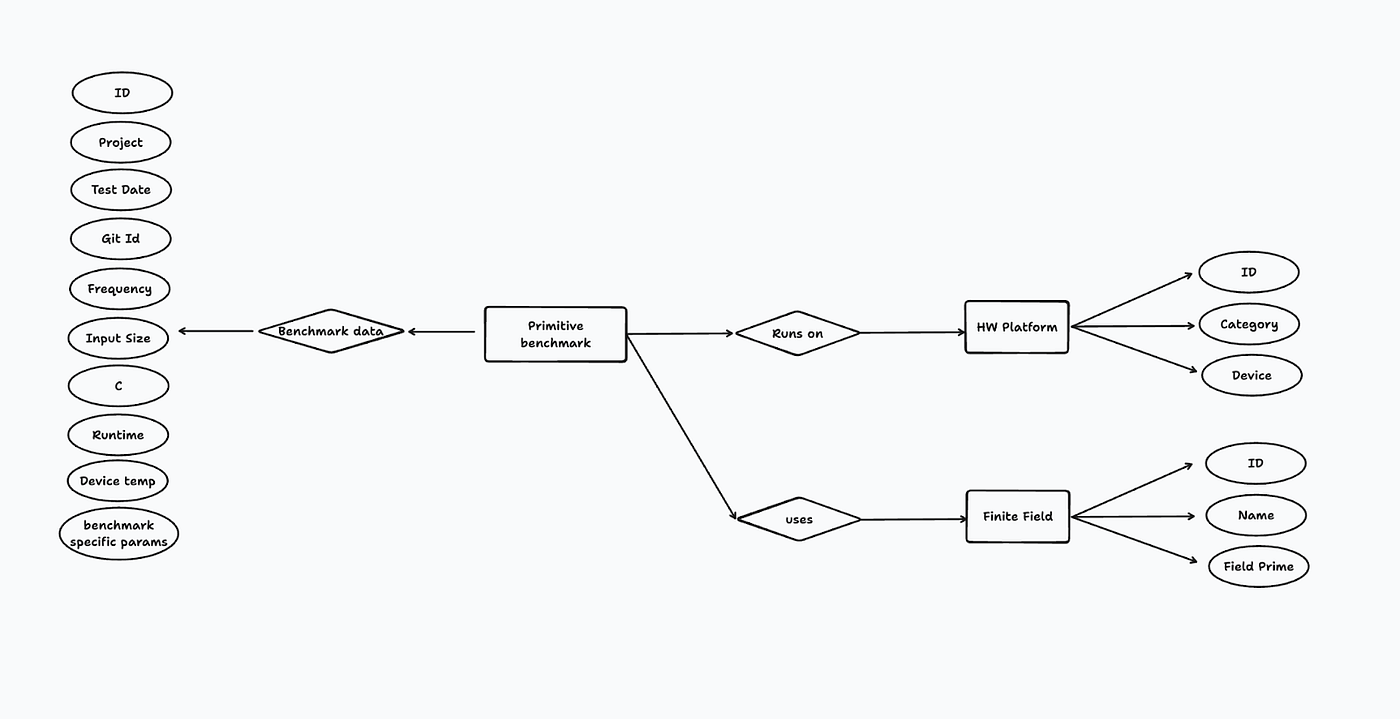
The hardware platform documents the type of device, driver, and machine specification upon which the benchmark ran. Finite field information stores details regarding the curve used for the benchmark. Benchmark data must include anything related to performance during runtime, device temperature, modular multiplications per second, input size and more. The diagram above illustrates the separate data structures collected.
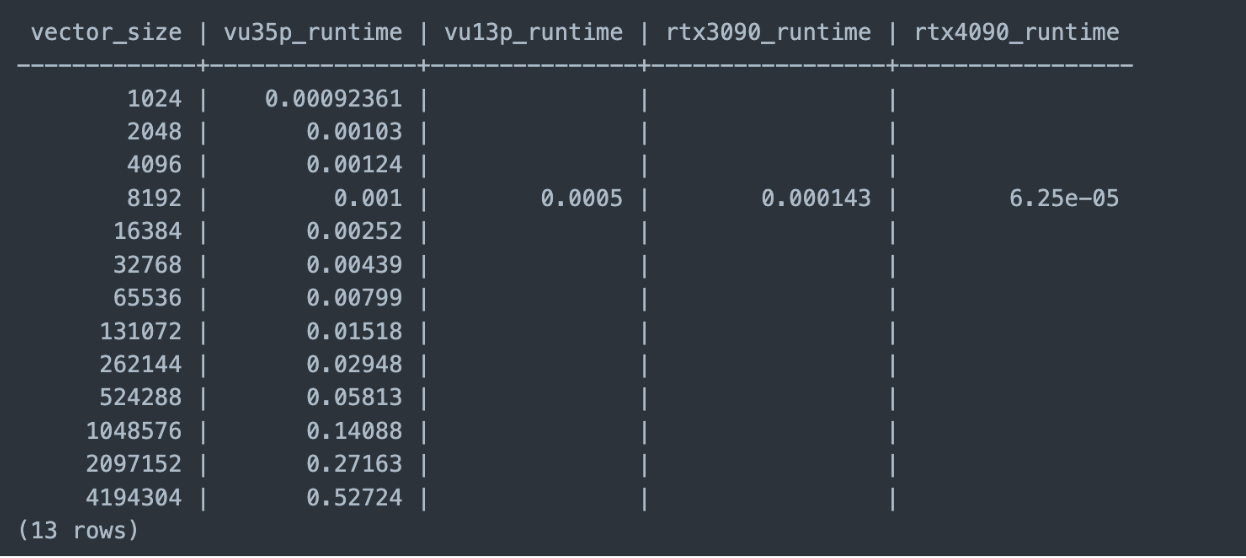
Creating a truly comprehensive benchmarking database is a community effort. Therefore the database is publicly available to read, and it’s also possible to submit entries for benchmarks you have conducted locally and wish to share. Instructions on doing so will follow.
Querying the Database
The database is hosted at benchmarks.ingonyama.com. User guest_user can query the database with read-only privileges.
Using command line tool psql, or any postgres UI, you can simply connect to the database and submit queries. For details, follow the guide on connecting to a benchmarks database.
Benchmarking Grøstl
Grøstl is a hash function developed as part of the NIST Cryptographic Hash Algorithm Competition. This hash function was recently highlighted as the main computational bottleneck in a new polynomial commitment scheme based on towers of binary fields. It is thus a prime candidate for FPGA acceleration. Our new implementation is open source: https://github.com/ingonyama-zk/ingo-hash
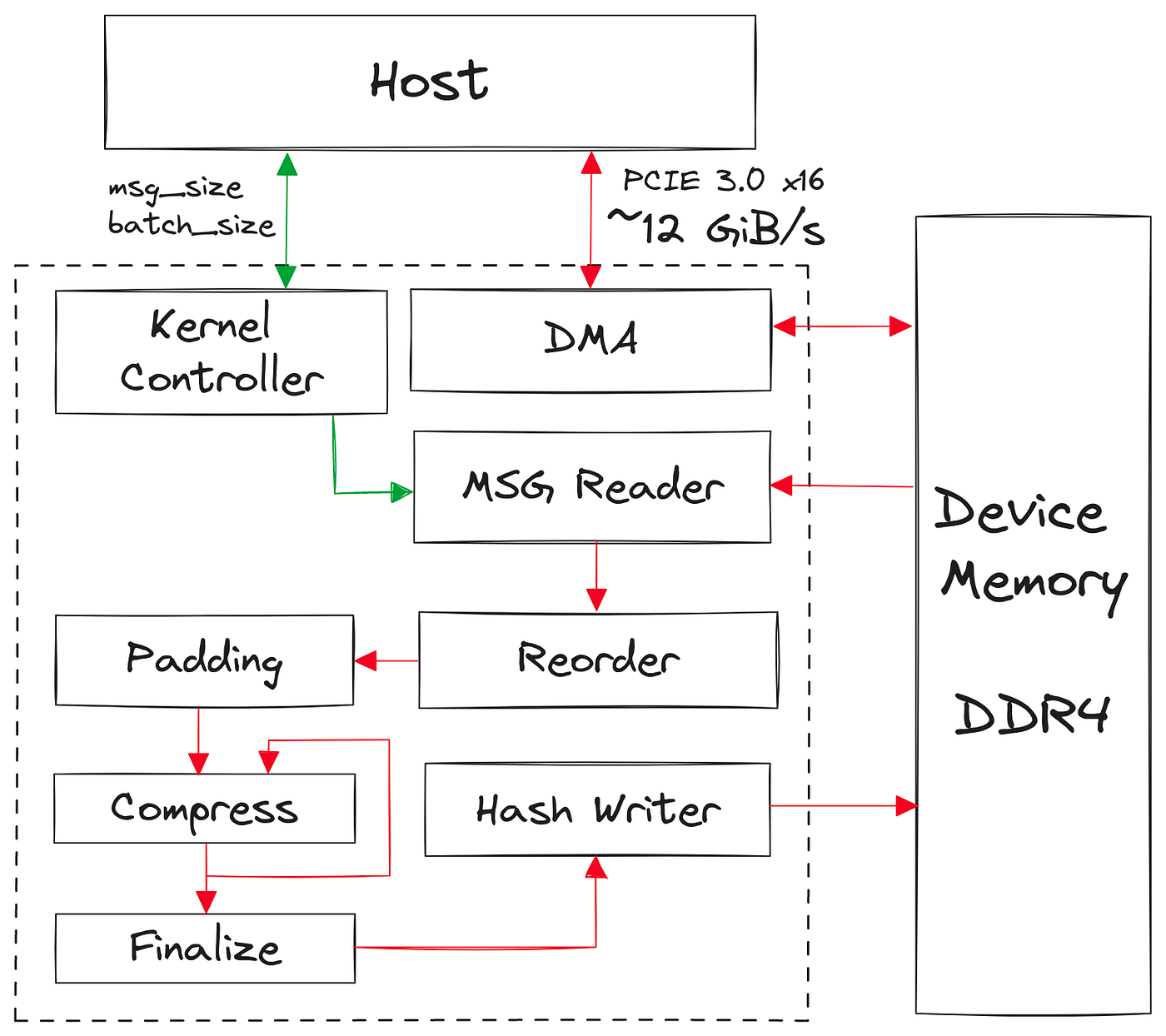
We will now demonstrate how to use the benchmarking toolkit to upload benchmark data and then process some interesting results.
Uploading Grøstl benchmarks
To load our benchmark data into the benchmarking toolkit we first need to create a table for the Grøstl hashing algorithm.
Now that the table has been created, we can load data into your database with a simple script.
Processing Grøstl benchmarks
Querying the database is simple.
The shell script above will output the benchmark data according to the query. You can try fetching this data yourself from the Ingonyama benchmarking database.

Automating Benchmark Data Collection
Focusing on ICICLE, a developer accelerating his prover may not only want to compare performance with alternative libraries, but also benchmark his ICICLE prover under inputs specific to some use case. Currently, this will require writing lots of code from scratch.
Another issue with current benchmarking tools is the lack of integration into CI/CD systems. ZK performance is sensitive to code changes, and it is important for an engineer to understand the effect that modifications have on the system.
Github Actions Integration
Github actions, along with the benchmarking toolkit, allows you to run benchmarks and constantly log performance data for every git commit.
The example above is running a ZK container along with a Poseidon hash benchmark from ICICLE Poseidon hash implementation. The benchmarking tool will log Poseidon hash performance; it’s even possible to alert the CI process if a benchmark is below a certain minimum performance expectation.
ZKBench
ZKBench is a rust library which can be used as a plugin for criterion benchmarks the popular Rust benchmarking library.
Using ZKBench you can integrate the benchmarking toolkit into your existing criterion benchmarks. ZKBench is capable of automatically collecting many of the data points required by the benchmarks.
Hosting Benchmark Database
The benchmark toolkit is completely open source and can be self-hosted.
If you are interested in hosting your own database, we made the process easy. Currently we support running the benchmark toolkit on an EC2 instance (or any server); however perhaps if demand calls for it, we will add automation support for RDS. We recommend using EC2 or a similar service as it’s cheaper.
Deploying your benchmark database is very easy and well documented in our guide.
We offer CloudFormation template, which makes it easy to deploy a free tier EC2 instance and even configures for you your network and security rules. To deploy the benchmark tool we use Docker Compose. After you configure your environment variables and install dependencies you simply need to run:
Your database should now be configured and ready to be integrated into your project. We provide some basic scripts for running benchmarks and testing your setup.

Disclaimer & Next Steps
If you are interested in adding your benchmark results you can either email us at benchmarks@ingonyama.com or submit an issue: https://github.com/ingonyama-zk/zk-benchmarks/issues.
The results must be reproducible by a third party (and ideally open source). Benchmarks should be stored in a json or xls file according to these guidelines.
While all results in the DB were measured and recorded by the Ingonyama team, we do not make any claims about these results as being our best results 😉
On our end, we plan on maintaining the public benchmarks DB, as well as automation tools such as ZKBench. As more benchmarks are performed, we will also refine our database tables as well to contain more detailed runtime data. Most importantly, we hope to soon normalize the database to reflect different forms of ZK-Scores.
Community feedback is highly appreciated 🙏🏻







