
A practical way to generate FAST Zero-Knowledge Proofs today
TL;DR:
In this blogpost we present the motivations, background, architecture, integration, and performance of ZK acceleration of Gnark using ICICLE.
Acceleration for ZKP seems to be a field being developed by wizards. Companies are presenting complex FPGA/ASIC designs that remain very far away from production, let alone developing integrations for existing infrastructure.
GPUs however are already being used to accelerate ZKPs (examples: Aleo, Filecoin). GPUs are characterized by competitive pricing and the benefits of a high-volume supply chain, making them readily available. GPUs also provide massive parallelization out of the box and crucially, have an abundance of developer frameworks, such as CUDA. These factors make GPUs a prime platform for ZK acceleration.
Motivations for Developing ICICLE
- SNARK proof generation is slow
- Modern SNARK frameworks (Rapidsnark, Halo2, Gnark, Arkworks only support CPU acceleration
- Hardware accelerators are easy to obtain (e.g cloud FPGA, gaming GPU) and relatively inexpensive
- It was shown that HW acceleration can successfully operate on ZK primitives e.g MSM, NTT (see Zprize)
- The logical next step is to integrate HW-based acceleration into SNARK frameworks
Introduction to ICICLE
We are excited to present ICICLE — an open-source library for Zero-Knowledge Proof Acceleration on CUDA-enabled GPUs.
Who is ICICLE for?
ICICLE is for developers who need to generate FAST Zero-Knowledge Proofs. It is also for protocol developers who want a GPU-accelerated crypto library without having to implement the low-level primitives from scratch. ICICLE is a first-of-its-kind library for ZKP, distributing acceleration to ZK developers like never before.
Why use ICICLE?
Unlike other ZK GPU acceleration projects, ICICLE is not application specific. ICICLE implements primitives such as MSM, NTT, polynomial operations, common hash functions, and more that are prevalent throughout ZK protocol implementations.
ICICLE provides users with an easy-to-use library that can be implemented into any Rust or Golang-based project and immediately (with a little engineering work) see massive performance improvements.
This article will guide you through our ICICLE <> Gnark integration. We will explore some of the key integration learning points from our experience developing ICICLE and integrating it into Gnark.

Overall System Design
ICICLE implements all primitives as CUDA kernels. These kernels construct our main APIs (illustrated below). In order to cater for simple integration and minimize developer overhead we maintain two high-level wrapper APIs, one in Rust and the other in Golang. These APIs abstract away memory management and provide easy access to the core API functions. Developers may still access the low-level CUDA API directly.
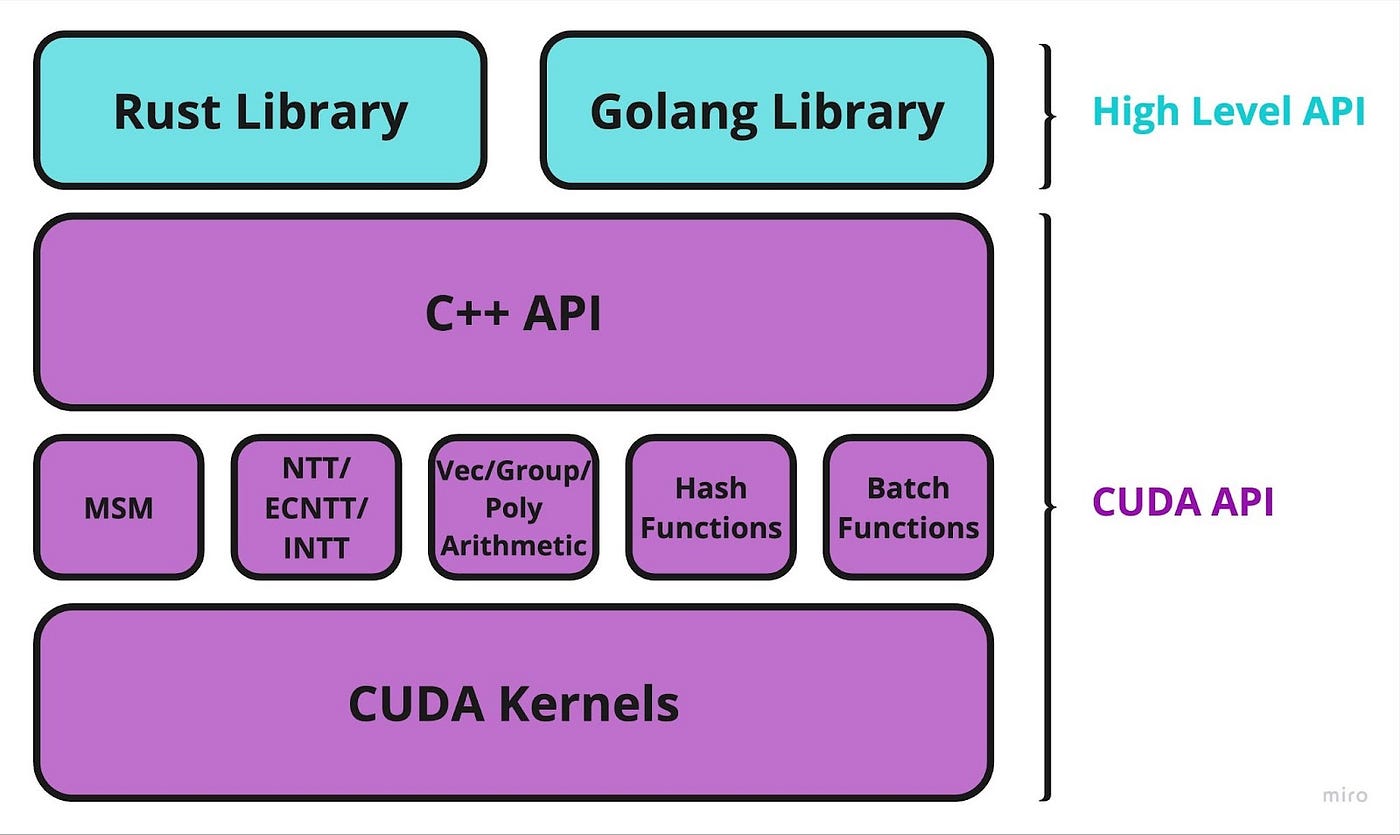
To illustrate the relation between CUDA Kernels and higher level CUDA API, we can have a look at commit_cuda_bls12_377. This C++ code calls a bucket msm algorithm we implemented, and within this CUDA code we call kernel’s like this one for example. These kernels represent parts of the algorithm that are meant to be executed in parallel.
(Commit_cuda_bls12_377 — A high-level API)
The Golang/Rust APIs, such as the goicicle library, wrap the high-level CUDA API and simplify integration into your existing codebase. There is no need to create C pointers, manage edge cases, or debug bindings; we have all that covered.
(Golang wrapper for msm on BN254)
Memory management
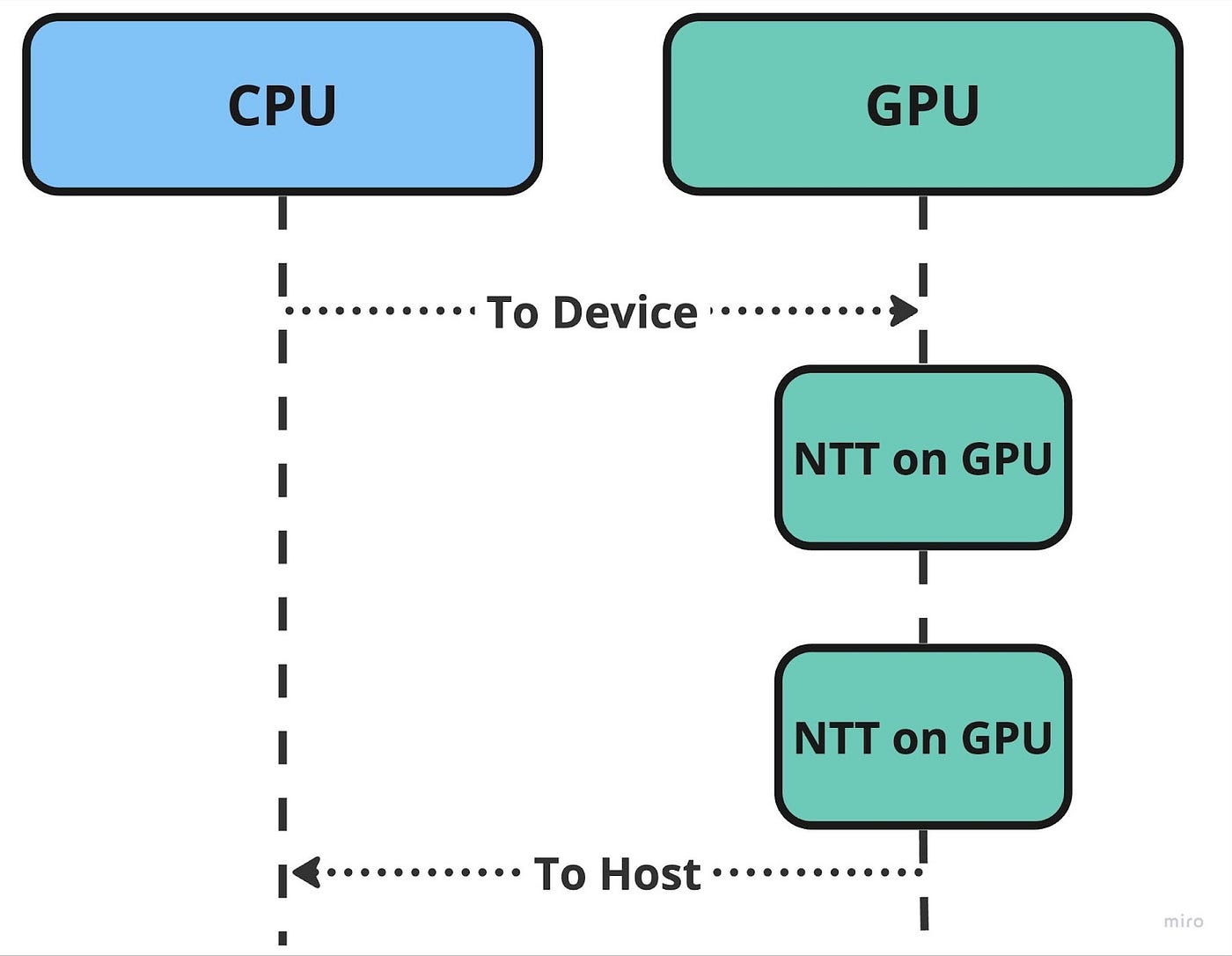
A fundamental guideline when using ICICLE involves minimizing data transfer frequency between the host (CPU) and the device (GPU). Data transfer between devices causes latency and will hurt performance. ICICLE is designed to encourage the use of on-device memory.
We encourage developers to structure their programs in a way that loads data onto the device once, performs as many operations as possible, and then retrieves the data back to the host.
Setting up ICICLE with Golang
ICICLE can be installed into your GO project simply by calling:
However there is one more extra step — we must compile a shared library from the CUDA code. This shared library will be linked to our GO library.
( An example of linking — we have this covered for you)
Setting this up is straightforward, all you need to do is compile the required shared library and export it to LD_LIBRARY_PATH=<shared_lib_dir/>
- Navigate to the location go get installed the ICICLE package (or clone the icicle project).
- Execute goicicle/setup.sh, and call it sh setup.sh <the_curve_you_want_to_compile>. If you wish to compile all curves simply call sh setup.sh.
- Make sure LD_LIBRARY_PATH contains your compiled shared libs path.
If LD_LIBRARY_PATH does not contain the path to your shared libs directory, export it manually export LD_LIBRARY_PATH=<shared_lib_dir/>
You can also use our MakeFile, documented more thoroughly here.
GOICICLE Primitives
Initially we are supporting three curves BN254, BLS12–377, and BLS12–381. We chose these curves due to their popularity in ZK systems.
Pre-generated constants
Many of our Curves contain pre-generated constants, with the goal being to prevent these constants from being generated during runtime, as it will hurt performance.
To make it easy to add new curve support we created a script that will generate for you all the necessary files to support a new curve (including CUDA code and Rust/Golang wrapper code).
Detailed instructions can be found here.
Packages
Curves are separated into packages. Each package contains Points, Fields, and algorithms such as MSM, NTT, polynomial operations, hash functions, and more. These packages are independent of one another. However, they share the same interface, and working with them should be the same.
Curves, fields, and points
ICICLE represents all Fields and Points in non-montgomery (short Weierstrass) format.

Fields
Our Field structs below are modeled after the CUDA fields so that it will be easy to convert between the two. In CUDA many of the field and curve parameters are pre-generated and loaded during runtime.
( Depending on the curve scalar and base size vary)
Points
We chose to use Projective and Affine coordinate notations for our points. Our algorithms are implemented from Affine (Affine input is converted to projective internally) to Projective.
In order to improve the compatibility of ICICLE with the existing Golang crypto ecosystem, we include methods such as toGnarkand fromGnarkas well as toJac (we plan to extract these compatibility functions to separate packages in the near future). The aim is to keep integration simple and fast.
We also support G2 Points and extension fields; G2 points have their own structs and methods.
G2 Points are also compatible with Gnark G2 points.
Algorithms
We currently support MSM, NTT, interpolation, Montgomery conversion, and a variety of arithmetics operations. We will cover most of these when reviewing the ICICLE / Gnark integration.
GOICICLE CUDA interface
The CUDA runtime API interface gives us access to the CUDA API through a Go interface.
At the time of writing this article, we only implemented a handful of useful memory management methods (you are welcome to add more if you find any are missing).
CudaMalloc
Allocate memory on the device according to a given size. It returns a pointer to the allocated memory.
CudaFree
Given an unsafe.Pointer it frees the memory allocated on the device.
CudaMemCpyHtoD
Copies memory from host (CPU) to device (GPU). It expects unsafe.Pointer so you should use CudaMalloc to allocate memory before calling CudaMemCpyHtoD.
CudaMemCpyDtoH
Copies memory from the device (GPU) to the host (CPU). It expects unsafe.Pointerso you should make sure to allocate memory using CudaMalloc.
Gnark and ICICLE: A match made in heaven :)
Let’s review the Gnark <> ICICLE integration.
Architecture overview
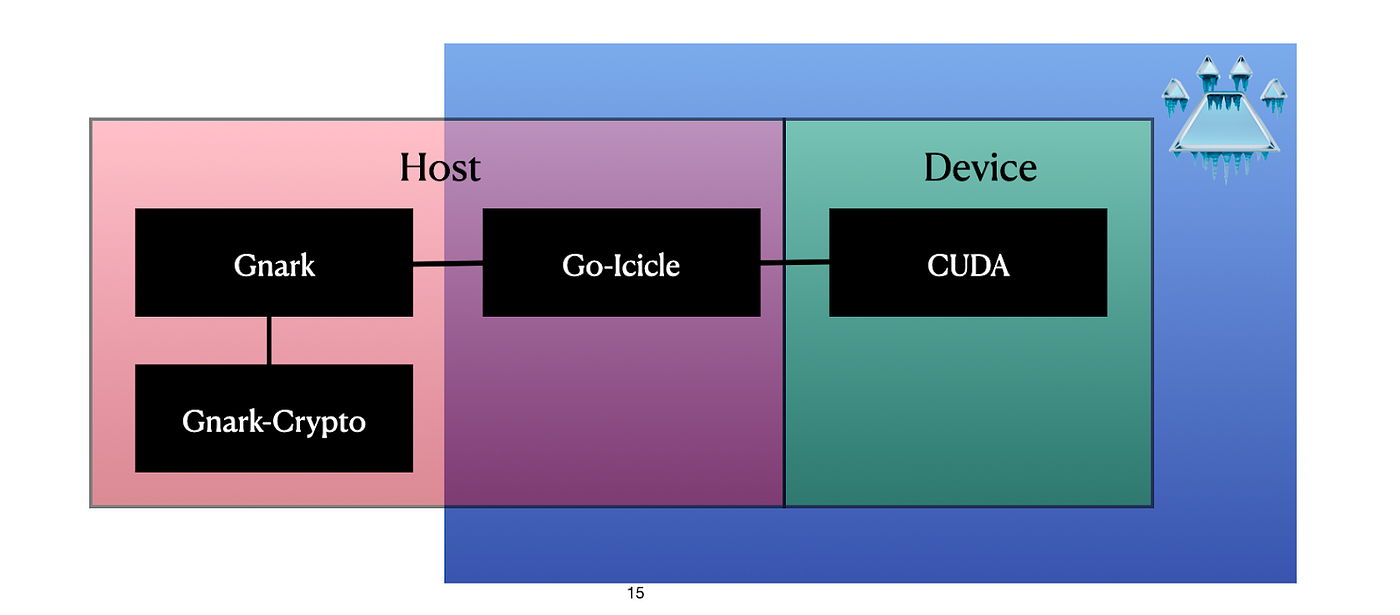
Gnark in its current form primarily relies on a conventional multicore CPU for all computations. However, we have implemented a design enhancement that incorporates a GPU into Gnark.
GOICICLE is used to transfer data between the Host and the Device. The ICICLE CUDA library is where we implement the actual acceleration and computation algorithms.
By offloading compute-intensive tasks to the GPU, we achieve a form of heterogeneous computing in which the CPU and GPU work together to optimize performance for different aspects of the application. This approach allows us to identify specific parts of the Gnark Groth16 protocol that may be significantly improved and accelerated with GPUs, without changing the rest of the protocol.
Gnark Overview
Gnark facilitates two provers for now: Plonk and Groth16. We focus on the Groth16 prover, and Plonk support is in the works.
Gnark facilitates two main functionalities: first, writing circuits in Golang, and second, generating zk-proofs and verifying them.
The process of generating a proof consists of multiple steps, the first being the setup phase, this phase constructs the SRS keys and sets up many variables we will need when generating the proof. In the second phase, we generate the proof, this phase involves the most computationally intensive operations, such as MSM and FFT.

Generating and verifying a proof in Gnark would look something like this:
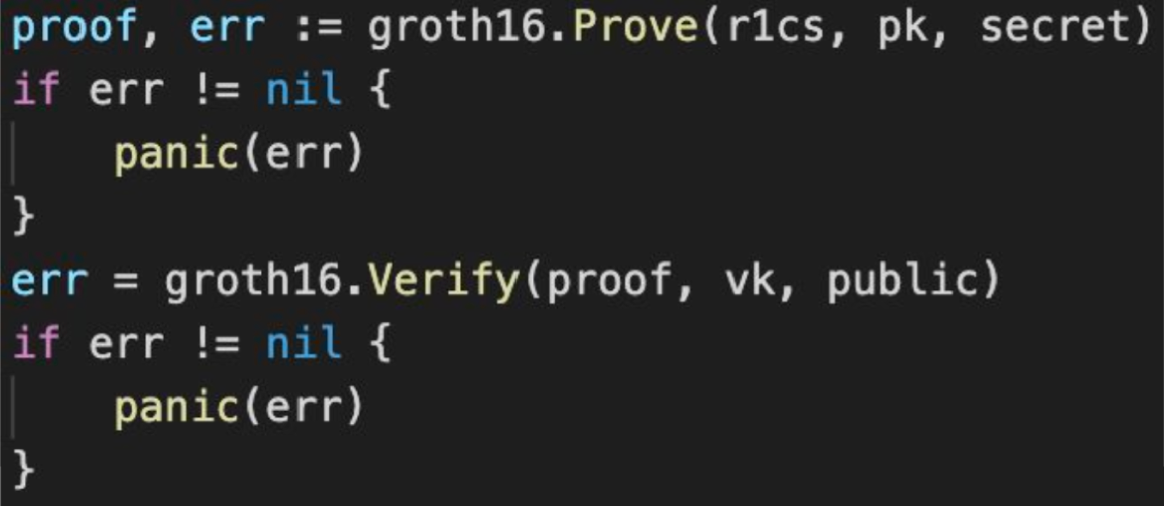
Where Vk and Pk are the verification and proving keys generated during setup, and r1cs is a constraint system generated from a circuit written using Gnarks circuit API.
Tackling the Setup
As discussed above, to lower latency we want to load data into the device memory as early as possible. During the setup we load G1, G2, Twiddle factors and Coset values.
(Source)
To load values into device memory we use CUDA functions CudaMalloc and CudaMemCpyHtoD:
(Source)
AffinePointFromMontgomery performs Montgomery conversions on GPU; if we didn’t do this during the setup phase we would need to perform these conversions during the prover runtime.
Similar actions are performed for G2Device, Domain, Twiddles, Twiddles Inv and CosetTables. All of these values are stored in GPU memory and accessed in the Proving stage.
The prover
The prover contains three main calculations: NTT, MSM, and polynomial operations.
NTT
In the original Gnark implementation NTT’s are performed sequentially on CPU.
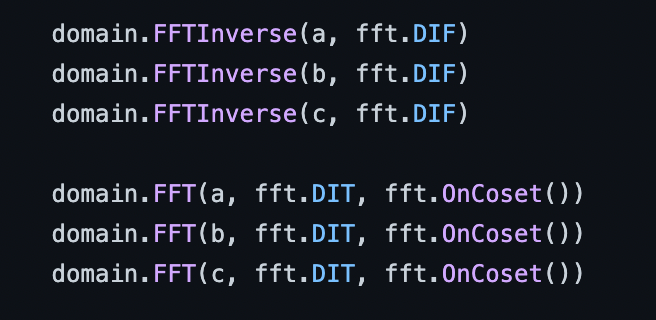
Using ICICLE we pair NTT and INTT and run three of them in parallel on the GPU.
(Source)
Pairing both INTT and NTT fully utilized the GPU and greatly improves performance.
Another point worth mentioning is the polynomial operations, which occur after performing the INTT and NTT pairs.
Since ICICLE also supports polynomial operations, we can simply implement this and avoid having to transfer data back from device to host, costing us precious runtime.
(Source)
This is a good example of how easy it is to use ICICLE to accelerate existing codebases without having to do a lot of work.
MSM
MSM’s are a bit of a different story since they are massive and consume many resources.
At the time of writing this article, we implemented an MSM bucket algorithm (similar to the one from ZPrize).
Due to the large size of MSM we found that they must consume all the GPU threads, thus interestingly enough it’s more efficient to run MSM in serial on GPU.
(Source)
MsmOnDevice uses many of the structures we initialized and loaded into device memory during setup time.
(Source)
Benchmarks
We ran our benchmarks on a setup containing:
GPU — RTX 3090 TI 24 GB,
CPU — I9 12900K
The circuits we benchmarked have a constraint size of > 2²³.
Our benchmarks achieve impressive results, and display how ICICLE can be used to accelerate a protocol with very little engineering effort.
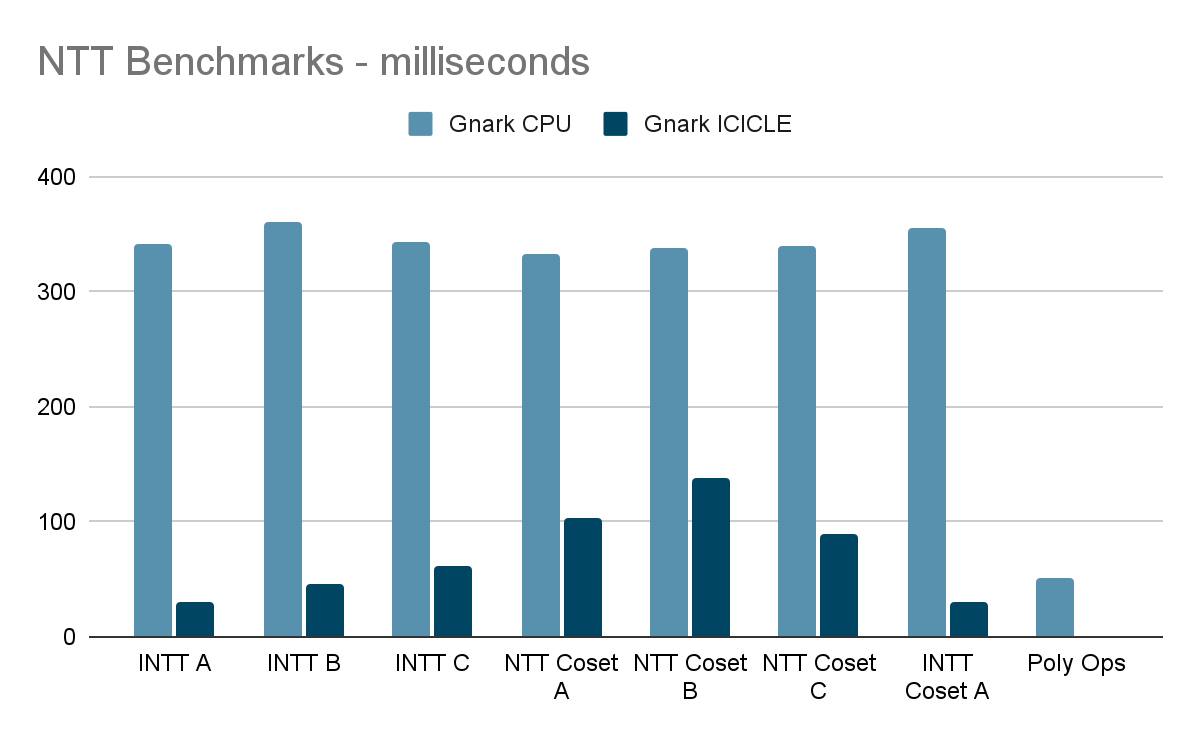
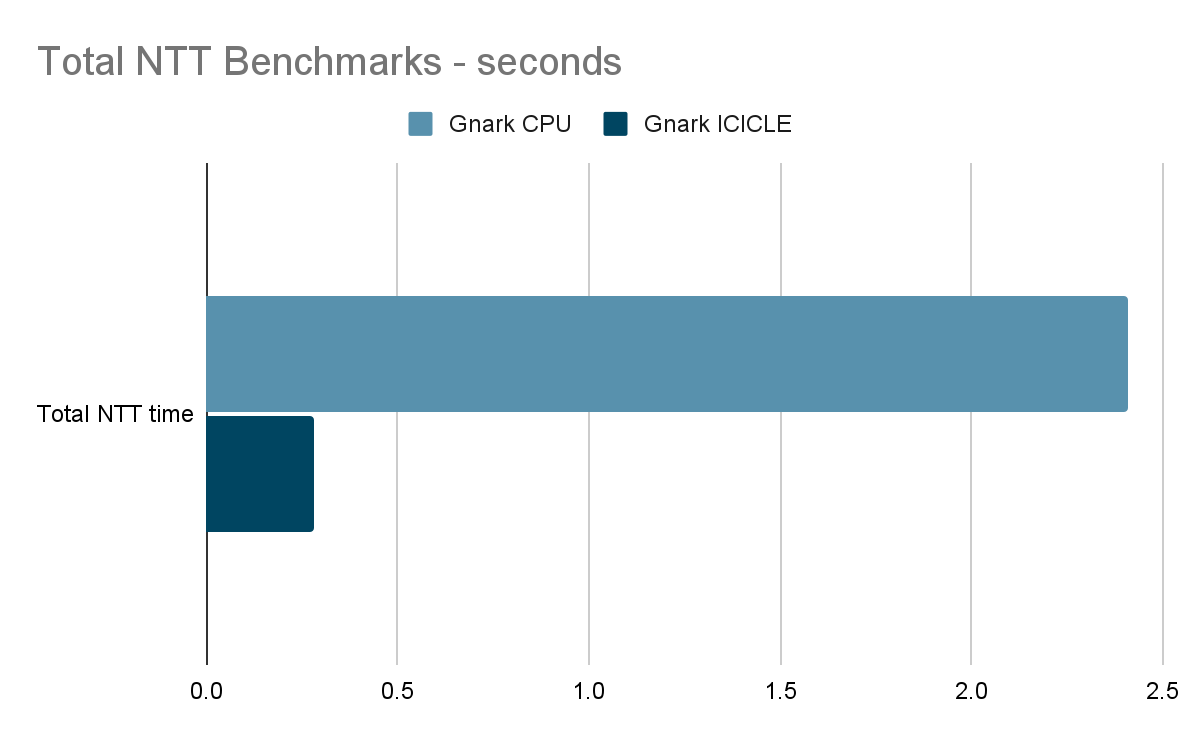
When reviewing the NTT results we see that times have been improved by x8. This is specifically due to our parallelization of NTT/INTT pairs. Polymorphic operations have been brought down to below 1 millisecond of compute time.
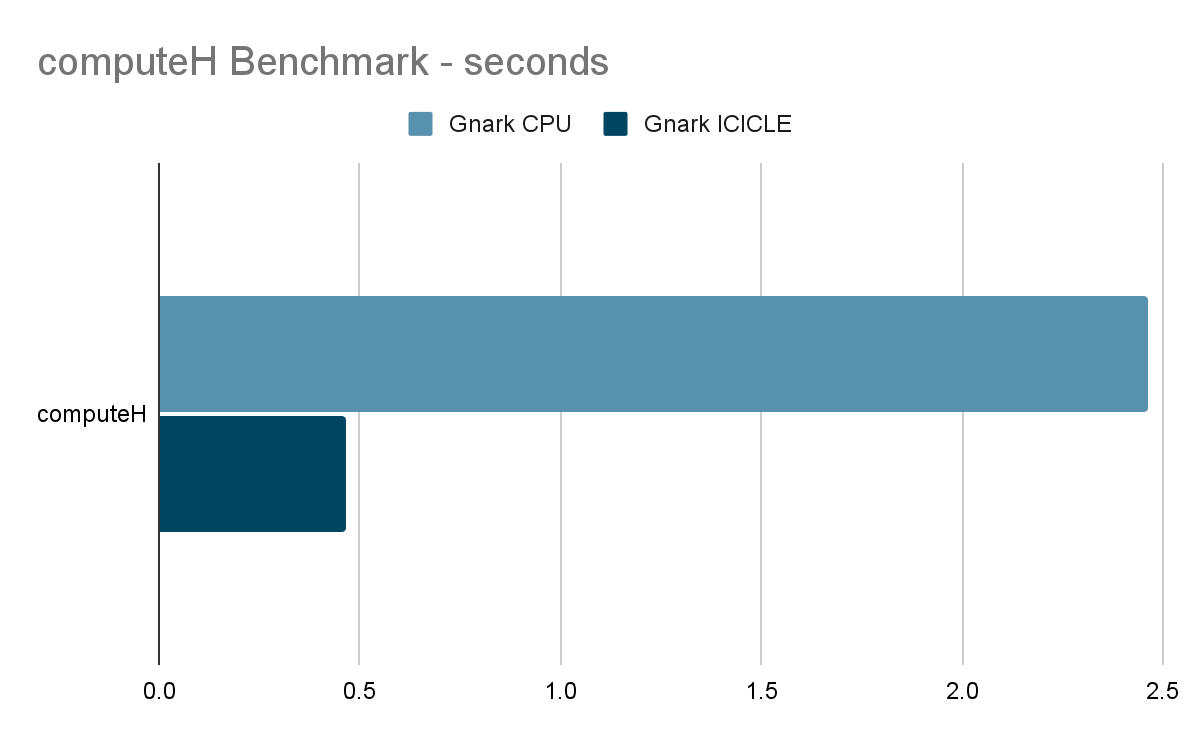
Total computeHtime (460 ms) also includes Covert / Copy of data to the device. These times could theoretically be reduced by a more comprehensive integration between Gnark and ICICLE. The current implementation still requires conversions between Montgomery representations (Gnark-crypto works in Montgomery and we work in non-Montgomery).
We achieved a 3X improvement with MSM speeds overall. MSM unlike NTT consumes the whole GPU due to the size of computation; simply scaling the number of GPUs in your system would double the speed. A setup with 2 GPUs for example would achieve a 6X easily.
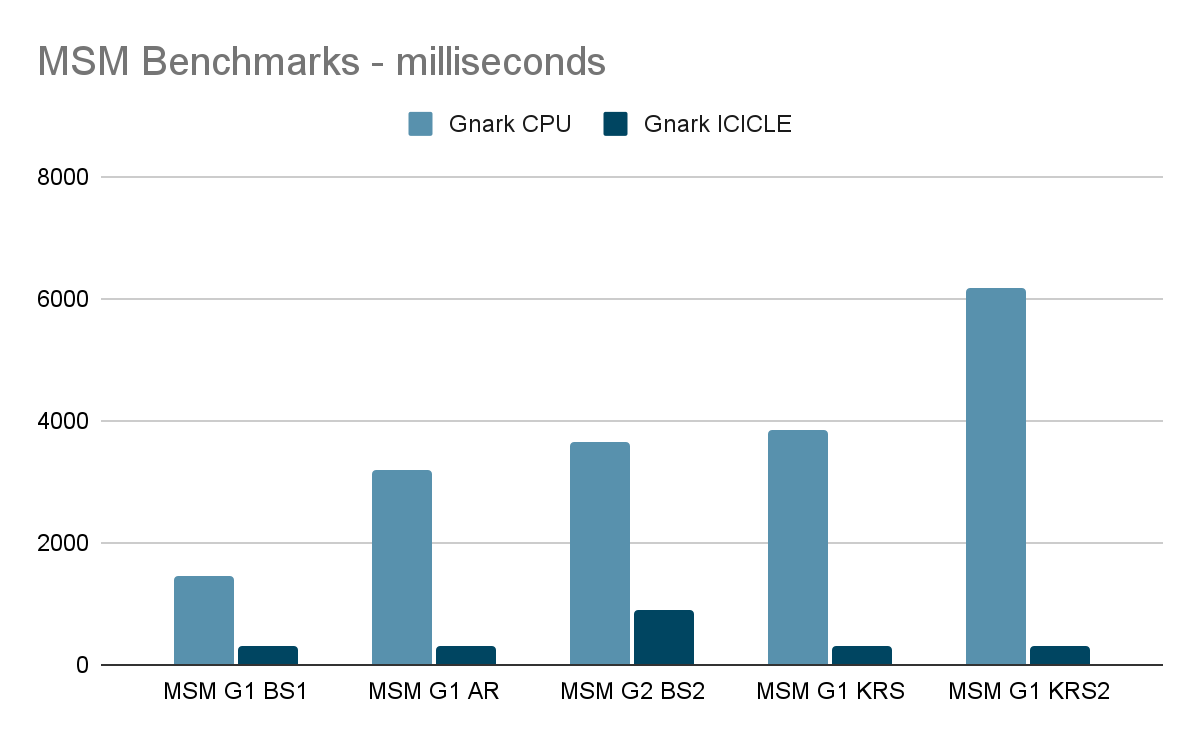
If you notice in the chart above when comparing MSM to MSM we see that there is a 10X improvement. While this is true, our MSMs are executed sequentially while Gnark’s implementation executes multiple MSMs in parallel. This is due to the reason stated above where our MSM implementation consumes the entire GPU.
So when we compare the full ICICLE Groth16 MSM runtime we see a 3X improvement, despite individual MSM being significantly faster.
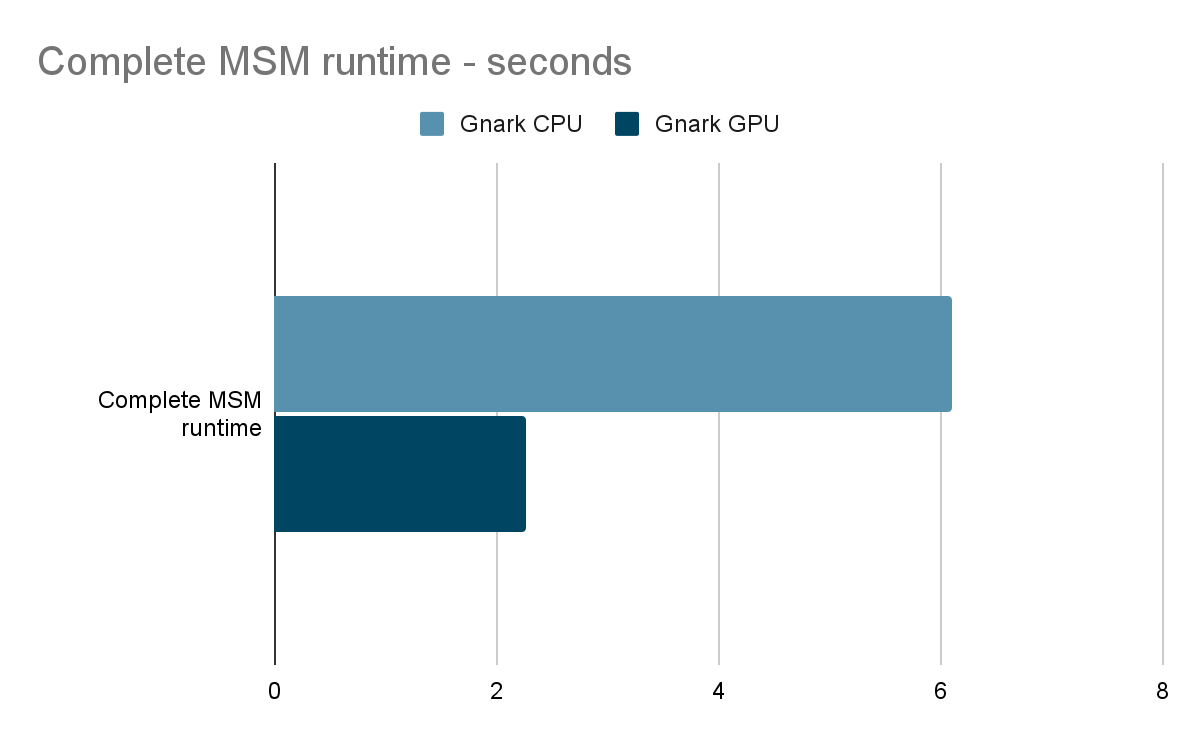
What is next?
ICICLE is still in its infancy. We have a road map of many new features in the works, from new algorithms to multi-GPU support. You can follow developments in our github.
We also have much to explore in the realms of deployment, benchmarking, and support for other protocols, Plonk being the natural next choice.
As usual, contributions, feedback, and questions are welcome — join the conversation with our team in the Ingonyama Discord channel!
This subject matter was also covered in a talk by Ingonyama CEO Omer Shlomovits at the zkParis event in 2023, part of Ethcc.
Follow Ingonyama
Twitter: https://twitter.com/Ingo_zk
YouTube: https://www.youtube.com/@ingo_zk
GitHub: https://github.com/ingonyama-zk
LinkedIn: https://www.linkedin.com/company/ingonyama
Join us: https://www.ingonyama.com/careers

